This notebook presents reproduction of pivotal Playing Atari with Deep Reinforcement Learning paper by DeepMind published in 2013.
Note that:
- DeepMind has not published source code for this paper
- Paper does not include all hyperparameters and implementation details
- Architecture does not use target network which makes everything much more difficult
Resources
- deep_q_rl - reproduction by Prof. Nathan Sprague in Theano. As far as I know this is the closest in spirit to original work on the internet. This was invaluable resource during development of this notebook.
Results¶
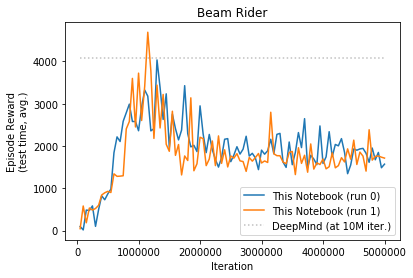
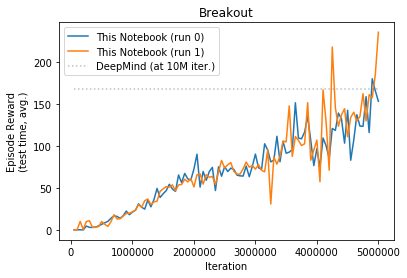
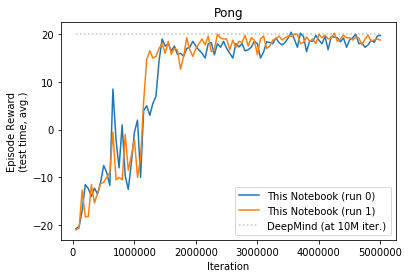
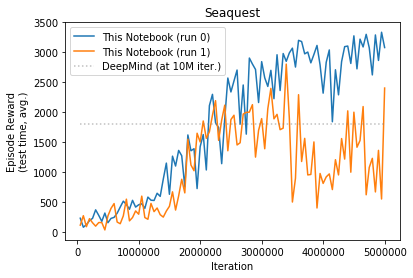
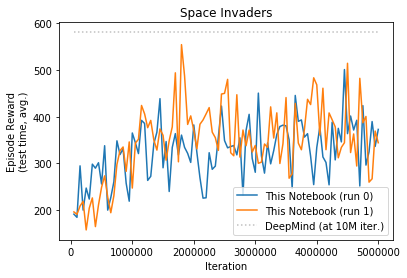
DeepMind run all games for 10M iterations, due to limited resources I only ran for 5M each game. I repeated each run twice. Table below show comparison of my results along with Prof. Sprague code and original DeepMind as reported in their paper.
| Beam Rider | Breakout | Enduro | Pong | Q*bert | Seaquest | Space Invaders | |
|---|---|---|---|---|---|---|---|
| Deep Mind (10M) | 4092 | 168 | 470 | 20 | 1952 | 1805 | 581 |
| Prof. Spraque (5M) | 1658 | 134 | 552 | 18 | 3210 | 1192 | 221 |
| This Notebook (5M) | 1765 | 140 | 549 | 19 | 2562 | 2150 | 357 |
Beam Rider
Breakout

Enduro


Pong

Q*bert
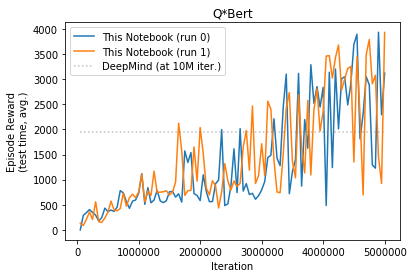

Seaquest

Space Invaders

Notes¶
Preprocessing in 2013 vs 2015 papers
| Modification | NIPS 2013 | Nature 2015 | Rainbow |
|---|---|---|---|
| Skip Frame | 4 | 4 | |
| Wrap + LazyFrame | 4 | 4 | |
| RGB -> Gray | ✓ | ||
| Scale + Crop | ✓ | ||
| Scale only | |||
| Reward Clip [-1,0,1] | ✓ | ||
| Episodic Life | |||
| Fire on Reset | |||
| Rand Noop Start |
Comments to table with results:
- Beam Rider - similar
- Breakout - similar
- Enduro - similar
- Pong - mine faster
- Q*Bert - prof slightly better
- Seaquest - mine slightly better
- Space Invaders - mine significantly better
Code¶
def q_learning(start_step, env, frames, gamma, eps_decay_steps, eps_target,
batch_size, model, mem, callback=None, trace=None, render=False, rng=None):
"""Episodic Semi-Gradient Sarsa
Params:
env - environment
ep - number of episodes to run
gamma - discount factor [0..1]
eps - epsilon-greedy param
model - function approximator, already initialised, with methods:
eval(state, action) -> float
train(state, target) -> None
"""
if rng is None:
rng = np.random
def policy(st, model, eps):
if rng.rand() > eps:
stack = np.stack([st]) # convert lazyframe to nn input shape [1, 84, 84, 4]
q_values = model.eval(stack)
return np.argmax(q_values)
else:
return env.action_space.sample()
if eps_decay_steps is not None:
eps_delta = (1-eps_target) / eps_decay_steps
eps = 1 - start_step*eps_delta
eps = max(eps, eps_target)
else:
eps = eps_target
assert len(mem) >= batch_size
tts_ = 0 # total time step
for e_ in itertools.count(): # count from 0 to infinity
S = env.reset()
episode_full_reward = 0
if render: env.render()
for t_ in itertools.count(): # count from 0 to infinity
A = policy(S, model, eps)
S_, R, done, info = env.step(A)
episode_full_reward += info['full-reward'] # unclipped reward
if render: env.render()
mem.append(S, A, R, S_, done)
if callback is not None:
callback(tts_+start_step, t_, S, A, R, done, info, eps, episode_full_reward, model, mem, trace)
states, actions, rewards, n_states, dones, _ = mem.get_batch(batch_size)
targets = model.eval(n_states)
targets = rewards + gamma * np.max(targets, axis=-1)
targets[dones] = rewards[dones] # return of next-to-terminal state is just R
model.train(states, actions, targets)
tts_ += 1
if tts_ >= frames:
return
if done:
break
S = S_
if eps > eps_target:
eps = max(eps - eps_delta, eps_target)
def evaluate(env, frames, episodes, eps, model, callback=None, trace=None, render=False, sleep=0, rng=None):
if rng is None:
rng = np.random
def policy(st, model, eps):
if rng.rand() > eps:
stack = np.stack([st]) # convert lazyframe to nn input shape [1, 84, 84, 4]
q_values = model.eval(stack)
return np.argmax(q_values)
else:
return env.action_space.sample()
per_episode_full_rewards = []
tts_ = 0 # total time step
for e_ in itertools.count(): # count from 0 to infinity
S = env.reset()
episode_full_reward = 0
if render:
env.render()
time.sleep(sleep)
for t_ in itertools.count(): # count from 0 to infinity
A = policy(S, model, eps)
S_, R, done, info = env.step(A)
episode_full_reward += info['full-reward'] # unclipped reward
if render:
env.render()
time.sleep(sleep)
if callback is not None:
raise # todo remove callback
callback(tts_, e_, t_, S, A, R, done, eps, model, None, trace)
if done:
per_episode_full_rewards.append(episode_full_reward)
break
if frames is not None and tts_ >= frames:
if len(per_episode_full_rewards) == 0: # if no complete episode,
per_episode_full_rewards.append(episode_full_reward) # then return what we have
return per_episode_full_rewards
S = S_
tts_ += 1
if episodes is not None and e_ >= episodes-1:
return per_episode_full_rewards
def prefill_memory(env, mem, steps=None, episodes=None, render=False, rng=None):
if rng is None:
rng = np.random
# Fill memory buffer using random policy
tts_ = 0
for e_ in itertools.count():
if episodes is not None and e_ >= episodes:
return
S = env.reset();
if render: env.render()
for t_ in itertools.count():
A = rng.randint(0, env.action_space.n) # random policy
S_, R, done, _ = env.step(A)
if render: env.render()
mem.append(S, A, R, S_, done)
tts_ += 1
if steps is not None and tts_ >= steps:
return
if done:
break
S = S_
Experiment Setup¶
Imports
import os
import time
import numpy as np
import matplotlib.pyplot as plt
import tables
import itertools
import collections
import PIL
import gym
import tensorflow as tf
config = tf.ConfigProto()
config.gpu_options.allow_growth=True
with tf.Session(config=config) as sess:
devs = sess.list_devices()
print('\n'.join([x.name for x in devs]))
Extra Imports (optional)
import pdb
# import sys
# sys.path.append('../Debug_NN')
# import importlib
# import tables_logger
# importlib.reload(tables_logger)
# %load_ext line_profiler
We will need callback to capture q-value array for whole state-action space at specified episodes.
class Trace():
def __init__(self, tf_summary_writer, log_metrics_every=None, test_states=None):
self.tf_summary_writer = tf_summary_writer
self.log_metrics_every = log_metrics_every
self.test_states = test_states
self.total_step = 0
self.ep_rewards = collections.OrderedDict()
self.ep_lengths = collections.OrderedDict()
self.ep_steps_per_sec = collections.OrderedDict()
self.ep_start_time = None
def push_summary(self, tag, simple_value, flush=False):
summary = tf.Summary()
summary.value.add(tag=tag, simple_value=simple_value)
self.tf_summary_writer.add_summary(summary, self.total_step)
if flush:
self.tf_summary_writer.flush()
def callback(total_time_step, tstep, st, act, rew_, done_, info, eps, ep_full_reward, model, memory, trace):
"""Called from gradient_MC after every episode.
Params:
episode [int] - episode number
tstep [int] - timestep within episode
model [obj] - function approximator
trace [list] - list to write results to"""
assert total_time_step == trace.total_step
if tstep == 0: # Episode just started
trace.ep_start_time = time.time()
if done_:
episode_time = time.time()-trace.ep_start_time
trace.ep_rewards[total_time_step] = ep_full_reward
trace.ep_lengths[total_time_step] = tstep
trace.ep_steps_per_sec[total_time_step] = tstep / episode_time
#
# Summaries
#
if trace.tf_summary_writer is not None:
# Episodic
if done_:
summary = tf.Summary()
summary.value.add(tag='Episodic/Ep_Reward', simple_value=ep_full_reward)
summary.value.add(tag='Episodic/Ep_Length', simple_value=tstep)
summary.value.add(tag='Episodic/StepsPerSec', simple_value=tstep / episode_time)
trace.tf_summary_writer.add_summary(summary, total_time_step)
# Metrics
if trace.log_metrics_every is not None and total_time_step % trace.log_metrics_every == 0:
trace.push_summary('Metrics/Epsilon', eps)
trace.push_summary('Metrics/Loss', model._model.log_loss)
trace.total_step += 1
Atari Helpers¶
# Print environment names
# for env in gym.envs.registry.all():
# if env.id.startswith('Q'):
# print(env.id)
# def preprocess(obs):
# img = PIL.Image.fromarray(obs)
# img = img.convert('L')
# img = img.resize([84, 84], resample=PIL.Image.NEAREST, box=[0,34,160,160+34])
# return np.array(img)
# PREPROCESS_OFFSET = 8 # Breakout
PREPROCESS_OFFSET = 16 # Pong, BeamRider, SpaceInvaders, Breakout?
def preprocess(obs):
img = PIL.Image.fromarray(obs)
img = img.convert('L')
img = img.resize([84, 84], resample=PIL.Image.BILINEAR,
box=[0, 210-160-PREPROCESS_OFFSET, 160, 210-PREPROCESS_OFFSET])
# box=(left, upper, right, lower)
return np.array(img)
# Test preprocess
# if False:
# env = gym.make('SpaceInvaders-v4')
# obs = env.reset()
# for i in range(50):
# obs, _, _, _ = env.step(0)
# plt.imshow(obs); plt.show()
# imgp2 = preprocess(obs)
# plt.imshow(imgp2, cmap='gray', vmin=0, vmax=255); plt.show()
def plot_frames(frames):
stack = np.array(frames) # convert LazyFrame to np.ndarray
assert stack.shape == (84, 84, 4)
fig, axes = plt.subplots(nrows=1, ncols=stack.shape[-1], figsize=[16,4])
for i in range(stack.shape[-1]):
axes[i].imshow(stack[:,:,i], cmap='gray', vmin=0, vmax=255)
axes[i].set_title('frame '+str(i))
plt.show()
class LazyFrames:
def __init__(self, frames):
assert isinstance(frames, list)
assert isinstance(frames[0], np.ndarray)
self._frames = frames # list of np.ndarray
def __array__(self, dtype=None):
# print('__ARRAY__ called')
merged = np.stack(self._frames, axis=-1)
if dtype is not None:
merged = merged.astype(dtype)
return merged
def __str__(self):
return str(np.round(np.stack(self._frames, axis=-1), decimals=4))
class WrapAtari:
def __init__(self, env):
assert env.observation_space == gym.spaces.Box(low=0, high=255, shape=[210,160,3], dtype=np.uint8)
self.observation_space = gym.spaces.Box(low=0, high=255, shape=[84, 84, 4], dtype=np.uint8)
self.action_space = env.action_space
self._env = env
self._frames = collections.deque(maxlen=4)
def reset(self):
raw_obs = self._env.reset() # 160x120 RGB
obs = preprocess(raw_obs) # 84x84 grayscale
for _ in range(self._frames.maxlen):
self._frames.append(obs) # replace all
return LazyFrames(list(self._frames))
def step(self, action):
assert self.action_space.contains(action)
raw_obs, rew, done, info = self._env.step(action)
obs = preprocess(raw_obs) # 84x84 grayscale
self._frames.append(obs)
assert 'full-reward' not in info
info['full-reward'] = rew
return LazyFrames(list(self._frames)), np.sign(rew), done, info
def seed(self, seed):
self._env.seed(seed)
def render(self, mode='human'):
return self._env.render(mode=mode)
def close(self):
self._env.close()
Experiment Setup¶
def setup_experiment(env_name, mem_size, mem_fill, tf_logdir=None, ignore_assert=False, seed=None):
global env
if tf_logdir is not None:
if not ignore_assert:
assert not os.path.exists(tf_logdir)
try: env.close()
except: pass
env = gym.make(env_name)
if env_name == 'MovingDot-v0': env.max_steps = 100
env = WrapAtari(env)
if seed is not None:
env.seed(seed)
PREPROCESS_OFFSET = 16
if env_name.startswith('Breakout'):
assert False
PREPROCESS_OFFSET = 8 # necessary?
tf.reset_default_graph()
if seed is not None:
tf.set_random_seed(seed)
session = tf.Session()
summary_writer = None
if tf_logdir is not None:
summary_writer = tf.summary.FileWriter(tf_logdir)
neural_net = TFNeuralNet(tf_session=session, tf_summary_writer=summary_writer,
nb_out=env.action_space.n, lr=0.0002, extended_debug=False)
model = TFFunctApprox(neural_net, st_low=0, st_high=255, rew_mean=0, rew_std=1, nb_actions=env.action_space.n)
if seed is None:
mem = Memory(max_len=mem_size, state_shape=(), state_dtype=object)
prefill_memory(env, mem, steps=mem_fill, render=False)
else:
mem = Memory(max_len=mem_size, state_shape=(), state_dtype=object, rng=np.random.RandomState(seed))
prefill_memory(env, mem, steps=mem_fill, render=False, rng=np.random.RandomState(seed))
test_states, _, _, _, _, _ = mem.get_batch(3200)
trace = Trace(tf_summary_writer=summary_writer,
log_metrics_every=500,
test_states=test_states)
if summary_writer is not None:
summary_writer.add_graph(session.graph)
summary_writer.flush()
session.run(tf.global_variables_initializer())
# neural_net.setup_logdb('outarray.h5', 20)
return env, trace, model, mem
def run_experiment(env, trace, model, mem, epoch_size, nb_total_steps, eps_decay_steps,
test_frames, test_episodes, stop_filename, render, rng=None):
if rng is None:
rng = np.random
while trace.total_step < nb_total_steps:
q_learning(trace.total_step, env, frames=epoch_size, gamma=.95, eps_decay_steps=eps_decay_steps, eps_target=0.1,
batch_size=32, model=model, mem=mem, callback=callback, trace=trace, render=render, rng=rng)
# model._model.save('./tf_models/Pong-v0_'+ str(trace.total_step) + '.ckpt')
ep_rewards = evaluate(env, test_frames, test_episodes, eps=0.05, model=model, render=render, rng=rng)
trace.push_summary(tag='Test/Reward_Avg', simple_value=np.mean(ep_rewards))
trace.push_summary(tag='Test/Reward_Max', simple_value=np.max(ep_rewards))
# q_test_values = model.eval(trace.test_states)
q_test_values = np.zeros(shape=[len(trace.test_states), env.action_space.n], dtype=np.float32)
for i in range(0, len(trace.test_states), 32):
q_test_values[i:i+32] = model.eval(trace.test_states[i:i+32])
q_test_average = np.mean(np.max(q_test_values, axis=-1)) # max over actions
trace.push_summary('Test/Q_Average', q_test_average, flush=True)
print('-'*80)
print('Epoch:', trace.total_step // epoch_size,
'\tTotal Step:', trace.total_step)
print('Num Episodes:', len(ep_rewards),
'\tTotal Reward:', np.sum(ep_rewards),
'\tAvg Reward:', np.mean(ep_rewards),
'\tMax Reward:', np.max(ep_rewards))
if os.path.exists(stop_filename):
break
Movning Dot¶
import moving_dot
env, trace, model, mem = setup_experiment(env_name='MovingDot-v0',
mem_size=10000, mem_fill=1000,
tf_logdir='tf_log_2/movingdot/new/speed2')
run_experiment(env, trace, model, mem, epoch_size=1000, nb_total_steps=20000, eps_decay_steps=10000,
test_frames=None, test_episodes=10, stop_filename='STOP_MOVINGDOT', render=False)
# %lprun -f q_learning -f model._model.backward \
# q_learning(trace.total_step, env, frames=1000, gamma=.95, eps_decay_steps=mem.max_len, eps_target=0.1, \
# batch_size=32, model=model, mem=mem, callback=callback, trace=trace, render=False)
ep_full_rewards = evaluate(env, frames=1050, episodes=None, eps=0.05, model=model, render=True)
env.close()
Pong¶
env, trace, model, mem = setup_experiment(env_name='PongDeterministic-v4',
mem_size=1000000, mem_fill=100,
tf_logdir='tf_log/pong/mine/1')
run_experiment(env, trace, model, mem, epoch_size=50000, nb_total_steps=5000000, eps_decay_steps=1000000,
test_frames=10000, test_episodes=None, stop_filename='STOP_PONG_1', render=False)
# model._model.save('./pong/mine/1/PongDeterministic-v4_5M.ckpt')
Breakout¶
env, trace, model, mem = setup_experiment(env_name='BreakoutDeterministic-v4',
mem_size=1000000, mem_fill=50000,
tf_logdir='tf_log_2/breakout/3')
run_experiment(env, trace, model, mem, epoch_size=50000, nb_total_steps=5000000, eps_decay_steps=1000000,
test_frames=10000, test_episodes=None, stop_filename='STOP_BREAKOUT_3', render=False)
run_experiment(env, trace, model, mem, epoch_size=50000, nb_total_steps=10000000, eps_decay_steps=1000000,
test_frames=10000, test_episodes=None, stop_filename='STOP_BREAKOUT_3', render=False)
# model._model.save('./tf_models/BreakoutDeterministic-v4_3_10M.ckpt')
Qbert¶
env, trace, model, mem = setup_experiment(env_name='QbertDeterministic-v4',
mem_size=1000000, mem_fill=50000,
tf_logdir='tf_log_2/qbert/3')
run_experiment(env, trace, model, mem, epoch_size=50000, nb_total_steps=5000000, eps_decay_steps=1000000,
test_frames=10000, test_episodes=None, stop_filename='STOP_QBERT_3', render=False)
run_experiment(env, trace, model, mem, epoch_size=50000, nb_total_steps=10000000, eps_decay_steps=1000000,
test_frames=10000, test_episodes=None, stop_filename='STOP_QBERT_3', render=False)
# model._model.save('./tf_models/QbertDeterministic-v4_3_10M.ckpt')
Beam Rider¶
env, trace, model, mem = setup_experiment(env_name='BeamRiderDeterministic-v4',
mem_size=200000, mem_fill=10000,
tf_logdir='tf_log_2/beam_rider/test')
run_experiment(env, trace, model, mem, epoch_size=25000, nb_total_steps=200000, eps_decay_steps=50000,
test_frames=10000, test_episodes=None, stop_filename='STOP_BEAM', render=True)
Function Approximators and Memory - Faster¶
class TFNeuralNet():
def __init__(self, tf_session, tf_summary_writer, nb_out, lr, extended_debug=False):
self._sess = tf_session
self._summary_writer = tf_summary_writer
self._extended_debug = extended_debug
self.nb_out = nb_out
self.lr = lr
self._log_filename = None
self._dict_layers = {}
self._timestep = 0
self.log_loss = 0
graph = tf.get_default_graph()
with tf.variable_scope('NeuralNet'):
with tf.variable_scope('ZZ_Inputs'):
self._x = tf.placeholder(name='xx', shape=[None, 84, 84, 4], dtype=tf.uint8)
self._y = tf.placeholder(name='yy', shape=[None], dtype=tf.float32)
self._a = tf.placeholder(name='aa', shape=[None], dtype=tf.int32)
self._x_scaled = tf.cast(self._x, tf.float32) / 255.0
tf.summary.histogram('DataIn', self._x)
tf.summary.histogram('Targets', self._y)
with tf.variable_scope('Conv_1'):
model = tf.layers.conv2d(self._x_scaled,
filters=16,
kernel_size=[8, 8],
strides=[4, 4],
padding='valid',
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(stddev=.01),
bias_initializer=tf.constant_initializer(value=.1))
tf.summary.histogram('Weights', graph.get_tensor_by_name('NeuralNet/Conv_1/conv2d/kernel:0'))
tf.summary.histogram('Biases', graph.get_tensor_by_name('NeuralNet/Conv_1/conv2d/bias:0'))
tf.summary.histogram('PreActivations', graph.get_tensor_by_name('NeuralNet/Conv_1/conv2d/BiasAdd:0'))
# Norms Ratio
WC1, _ = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='NeuralNet/Conv_1/conv2d')
WC1_bu = tf.get_variable('WC1_bu', trainable=False, initializer=WC1.initialized_value())
tf.summary.scalar( 'Update_Norm_Ratio', tf.norm(WC1 - WC1_bu) / tf.norm(WC1_bu) )
with tf.variable_scope('Conv_2'):
model = tf.layers.conv2d(model,
filters=32,
kernel_size=[4, 4],
strides=[2, 2],
padding='valid',
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(stddev=.01),
bias_initializer=tf.constant_initializer(value=.1))
tf.summary.histogram('Weights', graph.get_tensor_by_name('NeuralNet/Conv_2/conv2d/kernel:0'))
tf.summary.histogram('Biases', graph.get_tensor_by_name('NeuralNet/Conv_2/conv2d/bias:0'))
tf.summary.histogram('PreActivations', graph.get_tensor_by_name('NeuralNet/Conv_2/conv2d/BiasAdd:0'))
# Norms Ratio
WC2, _ = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='NeuralNet/Conv_2/conv2d')
WC2_bu = tf.get_variable('WC2_bu', trainable=False, initializer=WC2.initialized_value())
tf.summary.scalar( 'Update_Norm_Ratio', tf.norm(WC2 - WC2_bu) / tf.norm(WC2_bu) )
model = tf.layers.flatten(model)
with tf.variable_scope('Dense'):
model = tf.layers.dense(model,
units=256,
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(stddev=.01),
bias_initializer=tf.constant_initializer(value=.1))
tf.summary.histogram('Weights', graph.get_tensor_by_name('NeuralNet/Dense/dense/kernel:0'))
tf.summary.histogram('Biases', graph.get_tensor_by_name('NeuralNet/Dense/dense/bias:0'))
tf.summary.histogram('PreActivations', graph.get_tensor_by_name('NeuralNet/Dense/dense/BiasAdd:0'))
# Norms Ratio
WD, _ = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='NeuralNet/Dense/dense')
WD_bu = tf.get_variable('WD_bu', trainable=False, initializer=WD.initialized_value())
tf.summary.scalar( 'Update_Norm_Ratio', tf.norm(WD - WD_bu) / tf.norm(WD_bu) )
with tf.variable_scope('Output'):
self._y_hat = tf.layers.dense(model,
units=nb_out,
activation=None,
kernel_initializer=tf.random_normal_initializer(stddev=.01),
bias_initializer=tf.constant_initializer(value=.1))
tf.summary.histogram('Weights', graph.get_tensor_by_name('NeuralNet/Output/dense/kernel:0'))
tf.summary.histogram('Biases', graph.get_tensor_by_name('NeuralNet/Output/dense/bias:0'))
tf.summary.histogram('PreActivations', graph.get_tensor_by_name('NeuralNet/Output/dense/BiasAdd:0'))
# Norms Ratio
WO, _ = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='NeuralNet/Output/dense')
WO_bu = tf.get_variable('WO_bu', trainable=False, initializer=WO.initialized_value())
tf.summary.scalar( 'Update_Norm_Ratio', tf.norm(WO - WO_bu) / tf.norm(WO_bu) )
self._one_hot = tf.one_hot(self._a, nb_out, dtype=tf.int32, name='onehot')
self._y_hat_actions = tf.dynamic_partition(self._y_hat, self._one_hot, 2)[1]
self._loss = .5 * tf.losses.mean_squared_error(self._y, self._y_hat_actions)
tf.summary.scalar('ZZ_Loss', self._loss)
if not extended_debug:
#self._optimizer = tf.train.AdamOptimizer(learning_rate=lr)
assert lr == .0002
self._optimizer = tf.train.RMSPropOptimizer(lr, 0.99, 0.0, 1e-6)
self._train_op = self._optimizer.minimize(self._loss)
else:
with tf.control_dependencies([tf.assign(WC1_bu, WC1), tf.assign(WC2_bu, WC2),
tf.assign(WD_bu, WD), tf.assign(WO_bu, WO)]):
# Option 1: no gradient clipping
self._optimizer = tf.train.AdamOptimizer(learning_rate=lr)
self._grads_and_vars = self._optimizer.compute_gradients(self._loss)
self._train_op = self._optimizer.apply_gradients(self._grads_and_vars)
# Option 2: Global gradient clipping
#self._optimizer = tf.train.RMSPropOptimizer(learning_rate=0.00025, decay=0.0, momentum=0.95, epsilon=0.01)
#gradients, variables = zip(*self._optimizer.compute_gradients(self._loss))
#gradients, _ = tf.clip_by_global_norm(gradients, 1)
#self._train_op = self._optimizer.apply_gradients(zip(gradients, variables))
# Option 3: Per matrix
#self._optimizer = tf.train.RMSPropOptimizer(learning_rate=0.00025, decay=0.0, momentum=0.95, epsilon=0.01)
#gradients, variables = zip(*self._optimizer.compute_gradients(self._loss))
#gradients = [ None if gradient is None else tf.clip_by_norm(gradient, 1.0) for gradient in gradients ]
#self._train_op = self._optimizer.apply_gradients(zip(gradients, variables))
with tf.variable_scope('NeuralNet/Conv_1/'):
tf.summary.scalar('GradNorm', tf.norm(graph.get_tensor_by_name(
'NeuralNet/gradients/NeuralNet/Conv_1/conv2d/Conv2D_grad/tuple/control_dependency_1:0')))
with tf.variable_scope('NeuralNet/Conv_2/'):
tf.summary.scalar('GradNorm', tf.norm(graph.get_tensor_by_name(
'NeuralNet/gradients/NeuralNet/Conv_2/conv2d/Conv2D_grad/tuple/control_dependency_1:0')))
with tf.variable_scope('NeuralNet/Dense/'):
tf.summary.scalar('GradNorm', tf.norm(graph.get_tensor_by_name(
'NeuralNet/gradients/NeuralNet/Dense/dense/MatMul_grad/tuple/control_dependency_1:0')))
with tf.variable_scope('NeuralNet/Output/'):
tf.summary.scalar('GradNorm', tf.norm(graph.get_tensor_by_name(
'NeuralNet/gradients/NeuralNet/Output/dense/MatMul_grad/tuple/control_dependency_1:0')))
self._merged_summaries = tf.summary.merge_all()
def backward(self, x, y, a):
assert x.ndim == 4
assert y.ndim == 1
assert a.ndim == 1
assert x.shape == (32, 84, 84, 4)
if not self._extended_debug:
_, self.log_loss = \
self._sess.run([self._train_op, self._loss],
feed_dict={self._x: x, self._y: y, self._a: a})
else:
dict_layers, merged_summaries, self.log_loss, _ = \
self._sess.run([self._dict_layers, self._merged_summaries, self._loss, self._train_op],
feed_dict={self._x: x, self._y: y, self._a: a})
self._summary_writer.add_summary(merged_summaries, self._timestep)
if self._log_filename is not None:
tables_logger.append_log(self._log_filename, dict_layers)
self._timestep += 1
def forward(self, x):
return self._sess.run(self._y_hat, feed_dict={self._x: x})
def save(self, filepath):
saver = tf.train.Saver()
saver.save(self._sess, filepath)
def load(self, filepath):
saver = tf.train.Saver()
saver.restore(self._sess, filepath)
def setup_logdb(self, filename, batch_save):
if not self._extended_debug:
raise ValueError('Please enable extended_debug=True in constructor.')
self._log_filename = filename
graph = tf.get_default_graph()
dict_inout = {
#'batch_x' : cnn._x[0:batch_save,:,:,:],
'batch_y' : cnn._y[0:batch_save,:],
}
dict_conv_1 = {
'W': graph.get_tensor_by_name('NeuralNet/Conv_1/conv2d/kernel:0'),
'b': graph.get_tensor_by_name('NeuralNet/Conv_1/conv2d/bias:0'),
'dW': graph.get_tensor_by_name('NeuralNet/gradients/NeuralNet/Conv_1/conv2d/Conv2D_grad/tuple/control_dependency_1:0'),
'db': graph.get_tensor_by_name('NeuralNet/gradients/NeuralNet/Conv_1/conv2d/BiasAdd_grad/tuple/control_dependency_1:0'),
'z': graph.get_tensor_by_name('NeuralNet/Conv_1/conv2d/BiasAdd:0')[0:batch_save,:,:,:],
}
dict_conv_2 = {
'W': graph.get_tensor_by_name('NeuralNet/Conv_2/conv2d/kernel:0'),
'b': graph.get_tensor_by_name('NeuralNet/Conv_2/conv2d/bias:0'),
'dW': graph.get_tensor_by_name('NeuralNet/gradients/NeuralNet/Conv_2/conv2d/Conv2D_grad/tuple/control_dependency_1:0'),
'db': graph.get_tensor_by_name('NeuralNet/gradients/NeuralNet/Conv_2/conv2d/BiasAdd_grad/tuple/control_dependency_1:0'),
'z': graph.get_tensor_by_name('NeuralNet/Conv_2/conv2d/BiasAdd:0')[0:batch_save,:,:,:],
}
dict_dense = {
'W': graph.get_tensor_by_name('NeuralNet/Dense/dense/kernel:0')[:100,:50],
'b': graph.get_tensor_by_name('NeuralNet/Dense/dense/bias:0'),
'dW': graph.get_tensor_by_name('NeuralNet/gradients/NeuralNet/Dense/dense/MatMul_grad/tuple/control_dependency_1:0')[:100,:50],
'db': graph.get_tensor_by_name('NeuralNet/gradients/NeuralNet/Dense/dense/BiasAdd_grad/tuple/control_dependency_1:0'),
'z': graph.get_tensor_by_name('NeuralNet/Dense/dense/BiasAdd:0')[0:batch_save,:],
}
dict_output = {
'W': graph.get_tensor_by_name('NeuralNet/Output/dense/kernel:0'),
'b': graph.get_tensor_by_name('NeuralNet/Output/dense/bias:0'),
'dW': graph.get_tensor_by_name('NeuralNet/gradients/NeuralNet/Output/dense/MatMul_grad/tuple/control_dependency_1:0'),
'db': graph.get_tensor_by_name('NeuralNet/gradients/NeuralNet/Output/dense/BiasAdd_grad/tuple/control_dependency_1:0'),
'z': graph.get_tensor_by_name('NeuralNet/Output/dense/BiasAdd:0')[0:batch_save,:],
}
dict_metrics = {
'loss': cnn._loss,
}
self._dict_layers = {
'inout': dict_inout,
'conv_1': dict_conv_1,
'conv_2': dict_conv_2,
'dense': dict_dense,
'output': dict_output,
'metrics': dict_metrics,
}
tables_logger.create_log(filename, self._dict_layers, batch_save)
class TFFunctApprox():
def __init__(self, model, st_low, st_high, rew_mean, rew_std, nb_actions):
"""Q-function approximator using Keras model
Args:
model: Keras compiled model
"""
self._model = model
assert np.isscalar(st_low) and np.isscalar(st_high)
if nb_actions != model.nb_out:
raise ValueError('Output shape does not match action_space shape')
# normalise inputs
self._offsets = st_low + (st_high - st_low) / 2
self._scales = 1 / ((st_high - st_low) / 2)
self._rew_mean = rew_mean
self._rew_std = rew_std
def eval(self, states):
assert isinstance(states, np.ndarray)
assert states.ndim == 4
#assert states.shape == (32, 84, 84, 4) or states.shape == (1, 84, 84, 4) or states.shape == (10, 84, 84, 4)
inputs = states # (states - self._offsets) * self._scales
y_hat = self._model.forward(inputs)
return y_hat*self._rew_std + self._rew_mean
def train(self, states, actions, targets):
assert isinstance(states, np.ndarray)
assert isinstance(actions, np.ndarray)
assert isinstance(targets, np.ndarray)
assert states.ndim == 4
assert actions.ndim == 1
assert targets.ndim == 1
assert len(states) == len(actions) == len(targets)
targets = (targets-self._rew_mean) / self._rew_std # decreases range (std>1) to approx -1..1
inputs = states # (states - self._offsets) * self._scales
# all_targets = self._model.forward(inputs) # this range should be small already
# all_targets[np.arange(len(all_targets)), actions] = targets
# return self._model.backward(inputs, all_targets)
return self._model.backward(inputs, targets, actions)
class Memory:
"""Circular buffer for DQN memory reply. Fairly fast."""
def __init__(self, max_len, state_shape, state_dtype, rng=None):
"""
Args:
max_len: maximum capacity
"""
assert isinstance(max_len, int)
assert max_len > 0
if rng is None:
self._random = np.random # reuse numpy
else:
self._random = rng # use provided random number generator
self.max_len = max_len # maximum length
self._curr_insert_ptr = 0 # index to insert next data sample
self._curr_len = 0 # number of currently stored elements
state_arr_shape = [max_len] + list(state_shape)
self._hist_St = np.zeros(state_arr_shape, dtype=state_dtype)
self._hist_At = np.zeros(max_len, dtype=int)
self._hist_Rt_1 = np.zeros(max_len, dtype=float)
self._hist_St_1 = np.zeros(state_arr_shape, dtype=state_dtype)
self._hist_done_1 = np.zeros(max_len, dtype=bool)
def append(self, St, At, Rt_1, St_1, done_1):
"""Add one sample to memory, override oldest if max_len reached.
Args:
St [np.ndarray] - state
At [int] - action
Rt_1 [float] - reward
St_1 [np.ndarray] - next state
done_1 [bool] - next state terminal?
"""
self._hist_St[self._curr_insert_ptr] = St
self._hist_At[self._curr_insert_ptr] = At
self._hist_Rt_1[self._curr_insert_ptr] = Rt_1
self._hist_St_1[self._curr_insert_ptr] = St_1
self._hist_done_1[self._curr_insert_ptr] = done_1
if self._curr_len < self.max_len: # keep track of current length
self._curr_len += 1
self._curr_insert_ptr += 1 # increment insertion pointer
if self._curr_insert_ptr >= self.max_len: # roll to zero if needed
self._curr_insert_ptr = 0
def __len__(self):
"""Number of samples in memory, 0 <= length <= max_len"""
return self._curr_len
def get_batch(self, batch_len):
"""Sample batch of data, with repetition
Args:
batch_len: nb of samples to pick
Returns:
states, actions, rewards, next_states, next_done, indices
Each returned element is np.ndarray with length == batch_len
"""
assert self._curr_len > 0
assert batch_len > 0
indices = self._random.randint( # randint much faster than np.random.sample
low=0, high=self._curr_len, size=batch_len, dtype=int)
states = np.take(self._hist_St, indices, axis=0)
actions = np.take(self._hist_At, indices, axis=0)
rewards_1 = np.take(self._hist_Rt_1, indices, axis=0)
states_1 = np.take(self._hist_St_1, indices, axis=0)
dones_1 = np.take(self._hist_done_1, indices, axis=0)
if states.dtype == object and isinstance(self._hist_St[0], LazyFrames):
states = np.stack(states) # convert to single np.ndarray shape [batch_size, 4, 84, 84]
states_1 = np.stack(states_1) # where '4' is number of history frames presented to agent
return states, actions, rewards_1, states_1, dones_1, indices
def pick_last(self, nb):
"""Pick last nb elements from memory
Returns:
states, actions, rewards, next_states, done_1, indices
Each returned element is np.ndarray with length == batch_len
"""
assert nb <= self._curr_len
start = self._curr_insert_ptr - nb # inclusive
end = self._curr_insert_ptr # not inclusive
indices = np.array(range(start,end), dtype=int) # indices to pick, can be negative
indices[indices < 0] += self._curr_len # loop negative to positive
states = np.take(self._hist_St, indices, axis=0)
actions = np.take(self._hist_At, indices, axis=0)
rewards_1 = np.take(self._hist_Rt_1, indices, axis=0)
states_1 = np.take(self._hist_St_1, indices, axis=0)
dones_1 = np.take(self._hist_done_1, indices, axis=0)
if states.dtype == object and isinstance(self._hist_St[0], LazyFrames):
states = np.stack(states) # convert to single np.ndarray shape [batch_size, 4, 84, 84]
states_1 = np.stack(states_1) # where '4' is number of history frames presented to agent
return states, actions, rewards_1, states_1, dones_1, indices
below is just testing
Regression Test¶
To do regression test:
- restart kernel (optional?)
- run all cells up to and including Experiment Setup
- but DO NOT run cell with gpu_options.allow_growth = True
- run try_freeze_random_seeds
- run cells
- compare tensorflow graph with tf_log_2/movingdot/regression_seedXXXX_correct
import random
import gym.spaces
def try_freeze_random_seeds(seed, reproducible):
"""Will attempt to make execution fully reproducible
Params:
seed (int): Set random seeds for following modules:
random, numpy.random, tensorflow, gym.spaces
reproducible (bool): if True, then:
Disbale GPU by setting env. var. CUDA_VISIBLE_DEVICES to '-1'
Disable randomised hashing by setting PYTHONHASHSEED to '0'
Force single-threadeed execution in tensorflow
"""
#
# Environment variables
#
if reproducible:
os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # disable GPU
os.environ['PYTHONHASHSEED'] = '0' # force reproducible hasing
#
# Random seeds
#
print('Using random seed:', seed)
if seed is not None:
random.seed(seed)
np.random.seed(seed)
tf.set_random_seed(seed)
# always call this, if not called expicitly, defaults to seed==0
gym.spaces.seed(seed)
#
# Set TF session
#
if reproducible:
config = tf.ConfigProto()
config.intra_op_parallelism_threads=1
config.inter_op_parallelism_threads=1
sess = tf.Session(config=config)
try_freeze_random_seeds(1234, True)
import moving_dot
try_freeze_random_seeds(1234, True)
env, trace, model, mem = setup_experiment(env_name='MovingDot-v0',
mem_size=10000, mem_fill=1000,
tf_logdir='tf_log_2/movingdot/regression/regression_seed1234_3',
ignore_assert=False,
seed=1234)
# model._model.save('./gpuscale')
# model._model.load('./gpuscale')
# Test tensorflow init (seed=1234)
arr = np.array([[ 0.00404038, -0.0011101 , 0.00287149, -0.00742079],
[ 0.00373081, -0.00472571, 0.00222906, 0.0135657 ],
[ 0.00260243, -0.00149288, 0.00488387, -0.00979927],
[ 0.01998583, 0.00227076, -0.01760427, -0.00842011],
[ 0.00213073, 0.00090278, 0.02545193, -0.00737475],
[-0.01383904, 0.02202642, 0.00353555, 0.00174777],
[ 0.00866843, -0.00866704, -0.00883029, 0.01803745],
[-0.00380784, -0.01129672, 0.00063153, 0.0005096 ]],
dtype=np.float32)
WC1_tensor, _ = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='NeuralNet/Conv_1/conv2d')
WC1 = model._model._sess.run(WC1_tensor)
np.allclose(WC1[:,:,:,0][0], arr)
WC1[:,:,:,0][0]
rng = np.random.RandomState(1234)
run_experiment(env, trace, model, mem, epoch_size=200, nb_total_steps=2000, eps_decay_steps=2000,
test_frames=None, test_episodes=10, stop_filename='STOP_MOVINGDOT', render=False, rng=rng)
Test flat memory¶
Requires policy to be changed to:
raise # change q_learning to this!!!
def q_learning(start_step, env, frames, gamma, eps_decay_steps, eps_target,
batch_size, model, mem, callback=None, trace=None, render=False, rng=None):
def policy(st, model, eps):
if rng.rand() > eps:
if isinstance(st, LazyFrames):
stack = np.stack([st]) # convert lazyframe to nn input shape [1, 84, 84, 4]
q_values = model.eval(stack)
elif isinstance(st, np.ndarray):
q_values = model.eval(np.expand_dims(st, 0))
else:
raise ValueError('Unsupported state type')
return np.argmax(q_values)
else:
return env.action_space.sample()
class WrapAtari_2:
def __init__(self, env):
assert env.observation_space == gym.spaces.Box(low=0, high=255, shape=[210,160,3], dtype=np.uint8)
self.observation_space = gym.spaces.Box(low=0, high=255, shape=[84, 84, 4], dtype=np.uint8)
self.action_space = env.action_space
self._env = env
self._frames = collections.deque(maxlen=4)
def reset(self):
raw_obs = self._env.reset() # 160x120 RGB
obs = preprocess(raw_obs) # 84x84 grayscale
for _ in range(self._frames.maxlen):
self._frames.append(obs) # replace all
return np.stack(LazyFrames(list(self._frames)))
def step(self, action):
assert self.action_space.contains(action)
raw_obs, rew, done, info = self._env.step(action)
obs = preprocess(raw_obs) # 84x84 grayscale
self._frames.append(obs)
assert 'full-reward' not in info
info['full-reward'] = rew
return np.stack(LazyFrames(list(self._frames))), np.sign(rew), done, info
def seed(self, seed):
self._env.seed(seed)
def render(self, mode='human'):
return self._env.render(mode=mode)
def close(self):
self._env.close()
def setup_experiment_2(env_name, mem_size, mem_fill, tf_logdir=None, ignore_assert=False, seed=None):
global env
if tf_logdir is not None:
if not ignore_assert:
assert not os.path.exists(tf_logdir)
try: env.close()
except: pass
env = gym.make(env_name)
if env_name == 'MovingDot-v0': env.max_steps = 100
env = WrapAtari(env)
if seed is not None:
env.seed(seed)
PREPROCESS_OFFSET = 16
if env_name.startswith('Breakout'):
assert False
PREPROCESS_OFFSET = 8 # necessary?
tf.reset_default_graph()
if seed is not None:
tf.set_random_seed(seed)
session = tf.Session()
summary_writer = None
if tf_logdir is not None:
summary_writer = tf.summary.FileWriter(tf_logdir)
neural_net = TFNeuralNet_2(tf_session=session, tf_summary_writer=summary_writer,
nb_out=env.action_space.n, lr=0.0002, extended_debug=False)
model = TFFunctApprox(neural_net, st_low=0, st_high=255, rew_mean=0, rew_std=1, nb_actions=env.action_space.n)
if seed is None:
mem = Memory(max_len=mem_size, state_shape=env.observation_space.shape, state_dtype=env.observation_space.dtype)
prefill_memory(env, mem, steps=mem_fill, render=False)
else:
assert False
mem = Memory(max_len=mem_size, state_shape=(), state_dtype=object, rng=np.random.RandomState(seed))
prefill_memory(env, mem, steps=mem_fill, render=False, rng=np.random.RandomState(seed))
test_states, _, _, _, _, _ = mem.get_batch(3200)
trace = Trace(tf_summary_writer=summary_writer,
log_metrics_every=500,
test_states=test_states)
if summary_writer is not None:
summary_writer.add_graph(session.graph)
summary_writer.flush()
session.run(tf.global_variables_initializer())
# neural_net.setup_logdb('outarray.h5', 20)
return env, trace, model, mem
import moving_dot
env, trace, model, mem = setup_experiment_2(env_name='MovingDot-v0',
mem_size=10000, mem_fill=1000,
tf_logdir='tf_log_2/movingdot/new/speed_21')
run_experiment(env, trace, model, mem, epoch_size=1000, nb_total_steps=20000, eps_decay_steps=10000,
test_frames=None, test_episodes=10, stop_filename='STOP_MOVINGDOT', render=False)
# %load_ext line_profiler
# %lprun -f q_learning -f env.step \
# q_learning(trace.total_step, env, frames=1000, gamma=.95, eps_decay_steps=mem.max_len, eps_target=0.1, \
# batch_size=32, model=model, mem=mem, callback=callback, trace=trace, render=False)
Save / Load test¶
import pickle
def save_training(filename, trace, model, mem):
with open(filename+'.mem', 'wb') as fmem:
pickle.dump(mem, fmem, protocol=4)
tf_summary_writer = trace.tf_summary_writer
trace.tf_summary_writer = None
with open(filename+'.trace', 'wb') as ftrace:
pickle.dump(trace, ftrace, protocol=4)
trace.tf_summary_writer = tf_summary_writer
model._model.save(filename+'.ckpt')
def load_training(filename, trace, model, mem):
with open(filename+'.mem', 'rb') as fmem:
mem_tmp = pickle.load(fmem)
mem_tmp._random = mem._random
del mem
mem = mem_tmp
with open(filename+'.trace', 'rb') as ftrace:
trace_tmp = pickle.load(ftrace)
trace_tmp.tf_summary_writer = trace.tf_summary_writer
del trace
trace = trace_tmp
model._model.load(filename+'.ckpt')
model._model._timestep = trace.total_step
return trace, model, mem
Prepare and run first part of experiment
try_freeze_random_seeds(1234, True)
env, trace, model, mem = setup_experiment(env_name='MovingDot-v0',
mem_size=10000, mem_fill=1000,
tf_logdir='tf_log_2/movingdot/regression/regression_seed1234_3',
ignore_assert=False,
seed=1234)
rng = np.random.RandomState(1234)
run_experiment(env, trace, model, mem, epoch_size=200, nb_total_steps=1000, eps_decay_steps=2000,
test_frames=None, test_episodes=10, stop_filename='STOP_MOVINGDOT', render=False, rng=rng)
Save training
filename = './test/my_save'
save_training(filename, trace, model, mem)
rng_saved = rng
env_saved = env
Break stuff
mem._hist_At *= 0
trace.total_step = 0
model._model._timestep = 0
Restore
rng = rng_saved
env = env_saved
trace, model, mem = load_training(filename, trace, model, mem)
Run second part
run_experiment(env, trace, model, mem, epoch_size=200, nb_total_steps=2000, eps_decay_steps=2000,
test_frames=None, test_episodes=10, stop_filename='STOP_MOVINGDOT', render=False, rng=rng)
Pong NN Test¶
env = gym.make('PongDeterministic-v4')
env = WrapAtari(env)
mem = Memory(max_len=10000, state_shape=(), state_dtype=object)
prefill_memory(env, mem, one_episode=False)
print(len(mem))
states, actions, rewards, n_states, dones, _ = mem.pick_last(len(mem))
np.count_nonzero(rewards==-1)
np.count_nonzero(rewards==1)
np.count_nonzero(rewards==0)
del states
del n_states
cnn = TFNeuralNet(nb_out=6)
#cnn.setup_logdb('outarray.h5', 5)
model = TFFunctApprox(cnn, st_low=0, st_high=255, rew_mean=0, rew_std=1, nb_actions=6)
gamma = 0.95
batch_size = 32
THIS SHOULD CONVERGE
losses = []
for i in range(50000):
states, actions, rewards, n_states, dones, _ = mem.get_batch(batch_size)
targets = model.eval(n_states)
targets = rewards + gamma * np.max(targets, axis=-1)
targets[dones] = rewards[dones] # return of next-to-terminal state is just R
loss = model.train(states, actions, targets)
losses.append(loss)
if i % 25 == 0:
print(i, loss)
Test CNN Forward¶
env = gym.make('PongDeterministic-v4')
env = WrapAtari(env)
mem = Memory(max_len=1000, state_shape=(), state_dtype=object)
prefill_memory(env, mem)
states, actions, rewards_1, states_1, dones_1, indices = mem.get_batch(10)
for i in range(10):
print('----')
print(rewards_1[i])
plot_frames(states[i])
cnn = TFNeuralNet(nb_out=6)
states, actions, rewards_1, states_1, dones_1, indices = mem.get_batch(10)
states_nn = states / 255
cnn.forward(states_nn)
tf.trainable_variables()
writer = tf.summary.FileWriter(logdir='tf_log', graph=cnn._sess.graph)
writer.flush()
Test CNN Logging¶
cnn = TFNeuralNet(nb_out=6)
filename = 'outarray.h5'
cnn.setup_logdb(filename, batch_save=10)
tables_logger.print_log(filename)
Test Lazy Frame¶
A = np.array([1, 1, 1])
B = np.array([2, 2, 2])
C = np.array([3, 3, 3])
lf1 = LazyFrame([A, B])
lf2 = LazyFrame([B, C])
mem = np.zeros(shape=[10], dtype=object)
mem[0] = lf1
mem[1] = lf2
lf1._frames[0][0] = 4
lf1._frames
np.stack(mem[[0,1]])
np.array(mem[0])
Test Evaluate¶
env.close()
env = gym.make('PongDeterministic-v4')
env = WrapAtari(env)
cnn = TFNeuralNet(nb_out=6)
model = TFFunctApprox(cnn, st_low=0, st_high=255, rew_mean=0, rew_std=1, nb_actions=6)
def callback_disp(total_step, episode, tstep, st, act, rew_, done_, eps, model, memory, trace):
if done_:
print(total_step)
# pdb.set_trace()
ts = time.time()
tr = evaluate(env, 1000, None, eps=0.05, model=model, callback=callback_disp, render=True)
print(time.time() - ts)
env.close()
print(tr)
Test fill¶
env.close()
env = gym.make('PongDeterministic-v4')
env = WrapAtari(env)
mem = Memory(10000, (), object)
prefill_memory(env, mem, steps=2000)
env.close()
len(mem)
states, actions, rewards_1, states_1, dones_1, indices = mem.pick_last(len(mem))
print(np.count_nonzero(dones_1))
print('rew 1', np.count_nonzero(rewards_1==1))
print('rew 0', np.count_nonzero(rewards_1==0))
print('rew -1', np.count_nonzero(rewards_1==-1))
Test Mem Object¶
env = gym.make('PongDeterministic-v4')
env = WrapAtari(env)
env = gym.make('MovingDot3-v0')
env = WrapAtari(env)
lframes = env.reset()
lframes_, rew_, done_, _ = env.step(0)
mem = Memory(10, (), object)
mem.append(lframes, 0, rew_, lframes_, done_)
lframes = lframes_
lframes_, rew_, done_, _ = env.step(0)
mem.append(lframes, 0, rew_, lframes_, done_)
print(mem._hist_St)
print(mem._hist_At)
print(mem._hist_Rt_1)
print(mem._hist_St_1)
print(mem._hist_done_1)
arr = np.take(mem._hist_St, np.array([0, 1]), axis=0)
arr
np.stack(arr).shape
plot_frames(np.stack(arr)[0])
plot_frames(np.stack(arr)[1])
states, actions, rewards_1, states_1, dones_1, indices = mem.get_batch(2)
print(states.shape)
print(actions.shape)
print(rewards_1.shape)
print(states_1.shape)
print(dones_1.shape)
Test render¶
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import animation, rc
from IPython.display import HTML
def frames_render(env, frames, episodes, eps, model, callback=None, trace=None, render=True, sleep=0):
rendered_frames = []
def policy(st, model, eps):
if np.random.rand() > eps:
stack = np.stack([st]) # convert lazyframe to nn input shape [1, 84, 84, 4]
q_values = model.eval(stack)
return np.argmax(q_values)
else:
return env.action_space.sample()
total_reward = 0
tts_ = 0 # total time step
for e_ in itertools.count(): # count from 0 to infinity
S = env.reset()
if render:
rendered_frames.append(env.render(mode='rgb_array'))
#env.render()
time.sleep(sleep)
for t_ in itertools.count(): # count from 0 to infinity
# print(e_, t_)
A = policy(S, model, eps)
S_, R, done, info = env.step(A)
total_reward += info['full-reward']
if render:
rendered_frames.append(env.render(mode='rgb_array'))
#env.render()
time.sleep(sleep)
if callback is not None:
callback(tts_, e_, t_, S, A, R, done, eps, model, None, trace)
if done:
break
if frames is not None and tts_ >= frames:
return rendered_frames, total_reward
S = S_
tts_ += 1
if episodes is not None and e_ >= episodes-1:
return rendered_frames, total_reward
env.close()
evaluate(env, frames=None, episodes=1, eps=0.05, model=model, render=True)
rendered_frames, total_reward = frames_render(env, frames=None, episodes=1, eps=0.05, model=model, render=True)
print(total_reward)
plt.ioff()
fig = plt.figure(figsize=(rendered_frames[0].shape[1] / 72.0, rendered_frames[0].shape[0] / 72.0), dpi = 72)
ax = fig.add_subplot(111);
patch = ax.imshow(rendered_frames[0])
# plt.axis('off');
def animate(i):
patch.set_data(rendered_frames[i])
anim = animation.FuncAnimation(fig, animate, frames=len(rendered_frames), interval=20, repeat=False)
HTML(anim.to_html5_video())