$$ \huge{\underline{\textbf{ Linear Models }}} $$
$$ \large{\textbf{ Tile Coding }} $$
We are going to use Gradient MC algorithm from chapter 9.3 as a learning algorithm. Before continuing you should familiarise yourself properly with chapter 9.3. We will use the "fixed" version of Gradient MC, repeated here for reference.
One notable difference is that this version takes callback and trace arguments, so we can log results after each episode. This is used to reproduce figures in the book.
def gradient_MC(env, policy, ep, gamma, model, callback=None, trace=None):
"""Gradient Monte Carlo Algorithm
Params:
env - environment
policy - function in a form: policy(state)->action
ep - number of episodes to run
gamma - discount factor [0..1]
model - function approximator, already initialised, with method:
train(state, target) -> None
callback - function in a form: callback(episode, model, trace) -> None
trace - passed to callback, so it can log data into it
"""
for e_ in range(ep):
traj, T = generate_episode(env, policy)
Gt = 0
for t in range(T-1,-1,-1):
St, _, _, _ = traj[t] # (st, rew, done, act)
_, Rt_1, _, _ = traj[t+1]
Gt = gamma * Gt + Rt_1
model.train(St, Gt)
if callback is not None:
callback(e_, model, trace)
def generate_episode(env, policy):
"""Generete one complete episode.
Returns:
trajectory: list of tuples [(st, rew, done, act), (...), (...)],
where St can be e.g tuple of ints or anything really
T: index of terminal state, NOT length of trajectory
"""
trajectory = []
done = True
while True:
# === time step starts here ===
if done: St, Rt, done = env.reset(), None, False
else: St, Rt, done = env.step(At)
At = policy(St)
trajectory.append((St, Rt, done, At))
if done: break
# === time step ends here ===
return trajectory, len(trajectory)-1
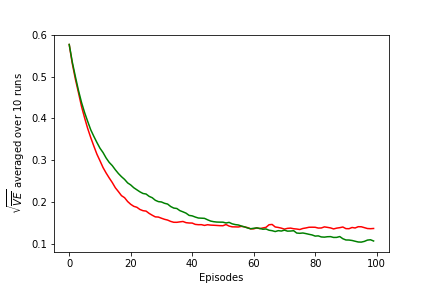 |
I realise this does not reproduce figure from the book, currently I'm not sure how exactly figure in the book was obtained. I am confident it is not because number of runs I used is 10 instead of 30 like in the book, or because I calculated VE every 100 episodes.
The only alternative implementation I found is by Shangtong Zhang (github). His graph looks a bit closer, but he decays step size over time, which obviously changes shape of curves. I modified his implementation to use fixed step size instead, and got same result as mine.
If anyone was able to reproduce results exactly (w/o adding/changing/removing anythign), please drop me a msg.
Environment Setup¶
All environment and plotting code is exactly the same as in chapter 9.3. All the code is available here: helpers_0905.py
import time
import numpy as np
import matplotlib.pyplot as plt
from helpers_0905 import LinearEnv, plot_linear
env = LinearEnv()
def policy(st):
return np.random.choice([0, 1])
Tile Coding - Introduction¶
We will be using tile coding implementation by Richard Sutton himself.
- documentation: http://incompleteideas.net/tiles/tiles3.html
- and source file: tiles3.py
import tiles3
Basic usage of this library is as follows:
- create Index Hash Table (IHT) - we work with small state space, so don't worry about collisions
- call tiles3.tiles(...) or tiles3.tileswrap(..) with IHT as first parameter - to obtain list of INDICES of activated tiles
- use indices to fetch data from e.g. weights array
All this is very similar to how AggregateFunctApprox worked in chapter 9.3
Let's see behaviour using one set of tiles. Tiles divide state space into [ 0.00-0.99, 1.0-1.99, 2.0-2.99, ... ]
iht = tiles3.IHT(2048)
result = []
print('state -> indices')
for state in np.arange(0, 2.5, 0.15):
indices = tiles3.tiles(iht, numtilings=1, floats=[state])
result.append(indices)
print('{0:.2f}'.format(state), ' -> ', indices)
Let's do the same with two set of tillings. First set of tiles divides space same as before, second set of tiles is offest by one-half.
iht = tiles3.IHT(2048)
result = []
print('state -> indices')
for state in np.arange(0, 2.5, 0.15):
indices = tiles3.tiles(iht, numtilings=2, floats=[state])
result.append(indices)
print('{0:.2f}'.format(state), ' -> ', indices)
And with four. Note I changed range. First set as before, sets 2,3,4 are now shifted by one-quater.
iht = tiles3.IHT(2048)
result = []
print('state -> indices')
for state in np.arange(0, 1.0, 0.07):
indices = tiles3.tiles(iht, numtilings=4, floats=[state])
result.append(indices)
print('{0:.2f}'.format(state), ' -> ', indices)
Tile Coding¶
class TileCodingFuncApprox():
def __init__(self, learn_rate, tile_size, nb_tilings, nb_states):
"""
Params:
learn_rate - step size, will be adjusted for nb_tilings automatically
tile_size - e.g. 200 for tiles to cover [1-200, 201-400, ...]
nb_tilings - how many tiling layers
nb_states - total number of states, e.g. 1000
"""
self._lr = learn_rate / nb_tilings
self._tile_size = tile_size
self._nb_tilings = nb_tilings
self._nb_states = nb_states
# calculate total number of possible tiles so we can allocate memory
# this calculation is valid for 1d space only!
nb_tiles_to_cover_state_space = (nb_states // tile_size) + 1 # +1 because tiles
num_tiles_total = nb_tiles_to_cover_state_space * nb_tilings # stick out on sides
self._num_total_tiles = num_tiles_total
self._iht = tiles3.IHT(num_tiles_total) # index hash table
self._w = np.zeros(num_tiles_total) # weights
def reset(self):
self._iht = tiles3.IHT(self._num_total_tiles) # clear index hash table
self._w = np.zeros(self._num_total_tiles) # clear weights
def evaluate(self, state):
st_scaled = (state-1) / self._tile_size # scale state to map to tiles correctly
tile_indices = tiles3.tiles(self._iht,
numtilings=self._nb_tilings,
floats=[st_scaled])
# Implementation #1
return np.sum(self._w[tile_indices]) # pick correct weights and sum up
# Implementation #2 # as lin. comb., equivalent to #1
# x = np.zeros(self._num_total_tiles)
# x[tile_indices] = 1
# return x @ self._w
def train(self, state, target):
st_scaled = (state-1) / self._tile_size # scale state to map to tiles correctly
tile_indices = tiles3.tiles(self._iht,
numtilings=self._nb_tilings,
floats=[st_scaled])
value = np.sum(self._w[tile_indices])
self._w[tile_indices] += self._lr * (target - value) # update active weights
Quick test: one set of tiles dividing states into groups of size 200 eacg
model = TileCodingFuncApprox(learn_rate=0.001, tile_size=200, nb_tilings=1, nb_states=1001)
gradient_MC(env, policy, ep=1000, gamma=1.0, model=model)
V = [model.evaluate(st) for st in range(1001)]
plot_linear(V, env=env)

Quick test #2: now with four sets of tiles, each offset by 1/4 of tile width. Note that small 'steps' are not completly independent, tiles still have same width as before.
model = TileCodingFuncApprox(learn_rate=0.001, tile_size=200, nb_tilings=4, nb_states=1001)
gradient_MC(env, policy, ep=1000, gamma=1.0, model=model)
V = [model.evaluate(st) for st in range(1001)]
plot_linear(V, env=env)

Reproduce Figure 9.10¶
Callback is called by gradient_MC every single timestep:
- only process every 100th episode (speed)
- compute V for all states
- compute Root Mean Squared Error (skip terminal state 0, state 1001 is out of boundry)
- append to rmse list
def callback(episode, model, trace):
"""Called from gradient_MC after every episode.
Params:
episode [int] - episode number
model [obj] - function approximator
trace [list] - list to write results to"""
if episode % 100 != 0: return
V = np.array([model.evaluate(st) for st in range(1001)]) # arr of float
err = np.sqrt(np.mean(np.power((np.array(V[1:]) - env.V_approx[1:]), 2))) # float
trace.append(err)
Define experiment
def experiment(runs, env, policy, ep, gamma, model, callback):
results = [] # dims: [nb_runs, nb_episodes]
for r in range(runs):
trace = [] # dim: [nb_episodes]
model.reset()
gradient_MC(env, policy, ep, gamma, model, callback=callback, trace=trace)
results.append(trace)
return np.average(results, axis=0)
Compute result for tilings=1. Average over 10 runs. This took ~6min.
ts = time.time()
model_1 = TileCodingFuncApprox(learn_rate=0.0001, tile_size=200, nb_tilings=1, nb_states=1001)
tiles_1 = experiment(10, env, policy, ep=10000, gamma=1.0, model=model_1, callback=callback)
print('Time took:', time.time()-ts)
And for tilings=50. Note that alpha is automatically divided by nb_tilings, so we are still in line with the book.
ts = time.time()
model_50 = TileCodingFuncApprox(learn_rate=0.0001, tile_size=200, nb_tilings=50, nb_states=1001)
tiles_50 = experiment(10, env, policy, ep=10000, gamma=1.0, model=model_50, callback=callback)
print('Time took:', time.time()-ts)
Plot results
fig = plt.figure()
ax = fig.add_subplot(111)
xx = np.array(range(len(tiles_1))) * 100
ax.plot(xx, tiles_1, color='red', label='State aggregation (one tiling)')
ax.plot(xx, tiles_50, color='green', label='Tile coding (50 tilings)')
ax.set_ylabel('$\sqrt{\overline{VE}}$ averaged over 10 runs')
ax.set_xlabel('Episodes')
# plt.savefig('assets/fig_0910.png')
ax.legend()
plt.show()

And plot final values for V
V_1 = [model_1.evaluate(st) for st in range(1001)]
V_50 = [model_50.evaluate(st) for st in range(1001)]
plot_linear(V_1, env)
plot_linear(V_50, env)

