Highlighted Projects
-
DQN Classic Control Use DQN to solve OpenAI Classic Control environments: MountainCar, Pendulum, CartPole, Acrobot and LunarLander
Code: DQN Classic Control
-

Playing Atari with Deep RL Reproduction of DeepMind pivotal paper "Playing Atari with Deep Reinforcement Learning" (2013).
Code not tidied, results coming soon.Code: DQN Atari 2013
Reinforcement Learning: An Introduction (2nd ed)
Implementation of algorithms from Sutton and Barto book Reinforcement Learning: An Introduction (2nd ed)
Chapter 2: Multi-armed Bandits
-
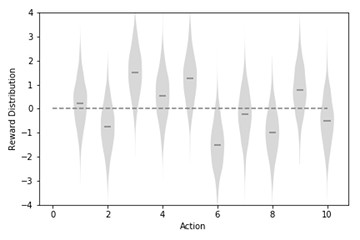
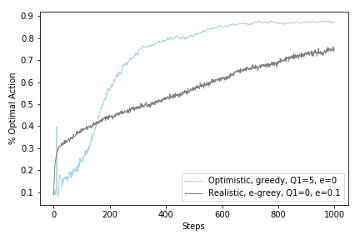
2.4 Simple Bandit Implementation of Simple Bandit Algorithm along with reimplementation of figures 2.1 and 2.2 from the book
Code: Simple Bandit
-
2.6 Tracking Bandit Implementation of Tracking Bandit Algorithm and recreation of figure 2.3 from the book
Code: Tracking Bandit
-
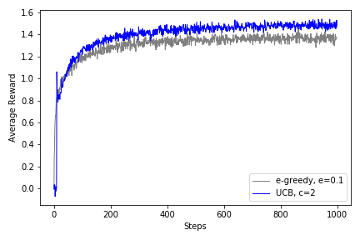
2.7 UCB Bandit Implementation of UCB Bandit Algorithm and recreation of figure 2.4 from the book
Code: UCB Bandit
-
2.8 Gradient Bandit Implementation of Gradient Bandit Algorithm and recreation of figure 2.5 from the book
Code: Gradient Bandit
-
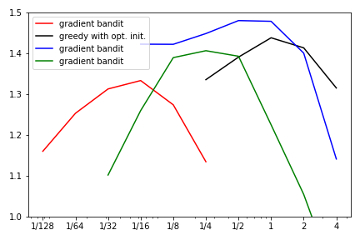
2.10 Summary Parameter study of bandit algorithms and recreation of figure 2.6 from the book
Code: Summary
Chapter 4: Dynamic Programming
-
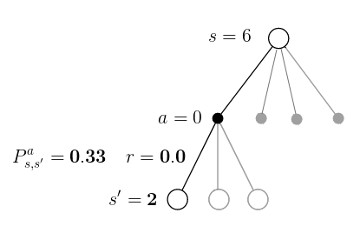
4.1 Iterative Policy Evaluation Implementation of Iterative policy Evaluation algorithm and demonstration on FrozenLake-v0 environment
-
4.3 Policy Iteration Implementation of Policy Iteration algorithm and demonstration on FrozenLake-v0 environment
Code: Policy Iteration
-
4.4 Value Iteration Implementation of Value Iteration algorithm and demonstration on FrozenLake-v0 environment
Code: Value Iteration
Chapter 5: Monte Carlo Methods
-
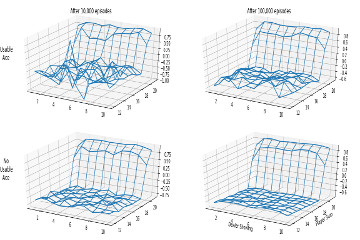
5.1 First-Visit MC Prediction Implementation of First-Visit MC Prediction algorithm, recreation of figure 5.1 and demonstration on Blackjack-v0 environment
-
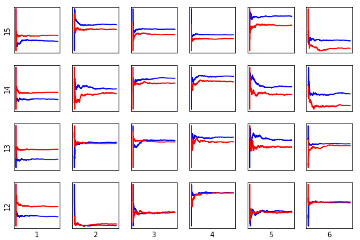
5.3 Monte Carlo ES Control Implementation of Monte Carlo ES Control algorithm, recreation of figure 5.2 and demonstration on Blackjack-v0 environment
Code: Monte Carlo ES Control
-
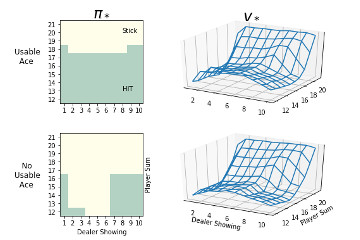
5.4 On-Policy First-Visit MC Control Implementation of On-Policy First-Visit MC Control algorithm and demonstration on Blackjack-v0 environment
Chapter 6: Temporal-Difference Learning
-
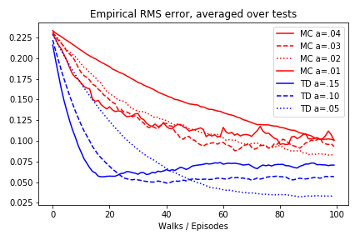
6.1 TD Prediction Implementation of TD Prediction algorithm, recreation of figure from example 6.2 and demonstration on Blackjack-v0 environment
Code: TD Prediction
-
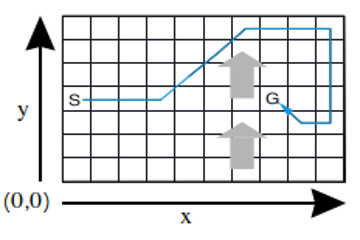
6.4 SARSA Implementation of SARSA algorithm, recreation of figure from example 6.5 and demonstration on Windy Gridworld environment
Code: SARSA
-
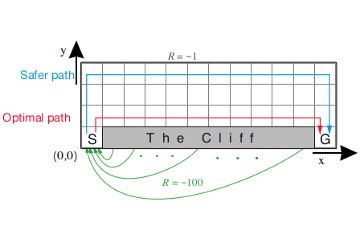
6.5 Q-Learning Implementation of Q-Learning algorithm and demonstration on Cliff Walking environment
Code: Q-Learning
Chapter 9: On-Policy Prediction with Approximation
-
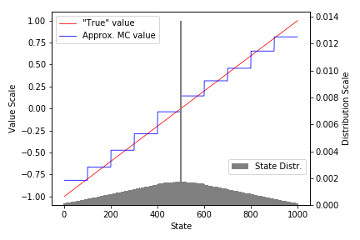
9.3a Gradient Monte Carlo Implementation of Gradient MC algorithm, recreation of figure 9.1 and example 9.1 and demonstration on Corridor environment
Code: Gradient Monte Carlo
-
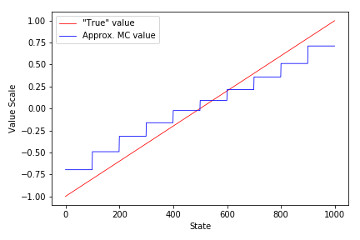
9.3b Semi-Gradient TD Implementation of Semi-Gradient TD algorithm, recreation of figure 9.2 and example 9.2 and demonstration on Corridor environment
Code: Semi-Gradient TD
-
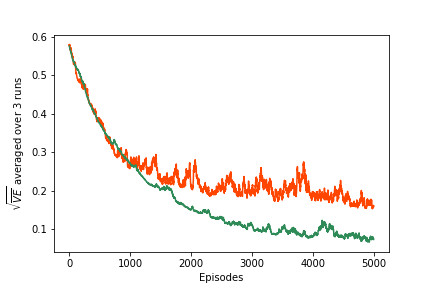
9.5a Linear Models - Poly. and Fourier Implementation of Linear Models with Polynomial and Fourier bases, recreation of figure 9.5 and demonstration on Corridor environment
-
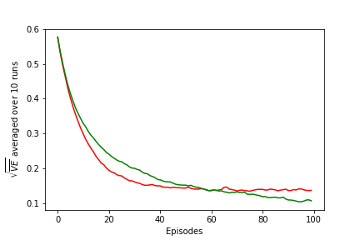
9.5b Tile Coding Implementation of Linear Model with Tile Coding, recreation of figure 9.10 and demonstration on Corridor environment
Code: Tile Coding
-
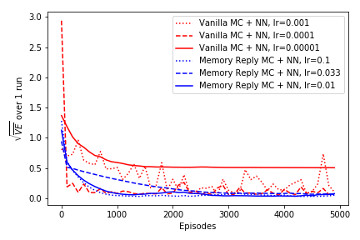
Bonus: Basic ANN Implementation of Gradient MC with Artificial Neural Network function approximation and demonstration on Corridor environment
Code: Gradient MC ANN
Chapter 10: On-Policy Control with Approximation
-
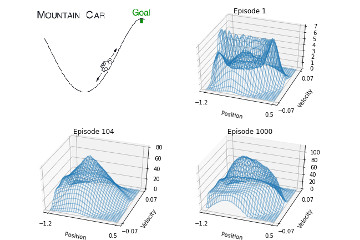
10.1 Episodic Semi-Gradient SARSA Implementation of Episodic Semi-Gradient SARSA algorithm, recreation of figures 10.1 and 10.2 and demonstration on MountainCar-v0 environment
Chapter 13: Policy Gradient Methods
-
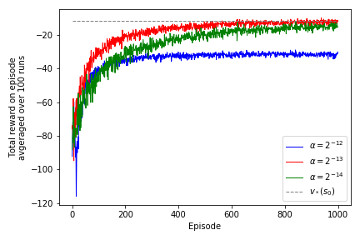
13.3 REINFORCE: MC Policy Gradient Implementation of REINFORCE algorithm, recreation of figure 13.1 and demonstration on Corridor with switched actions environment
Code: REINFORCE
-
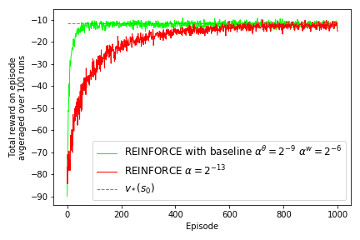
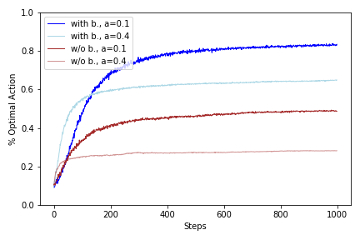
13.4 REINFORCE with Baseline Implementation of REINFORCE with Baseline algorithm, recreation of figure 13.4 and demonstration on Corridor with switched actions environment
Code: REINFORCE with Baseline
-
13.5a One-Step Actor-Critic Implementation of One-Step Actor-Critic algorithm, we revisit Cliff Walking environment and show that Actor-Critic can learn the optimal path
Code: One-Step Actor-Critic
-
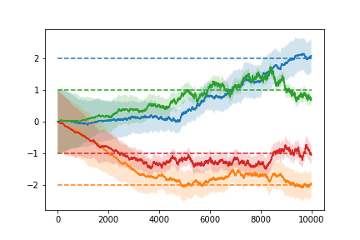
13.7 Continuous Actions Implementation of Policy Parametrization for Continuous Actions with examples on Continuous Bandit
Code: Continuous Actions
UCL Course on RL (2016) by David Silver
A more in-depth treatment of selected concepts from David Sivler video lectures and Sutton and Barto book. This is advanced material.
-
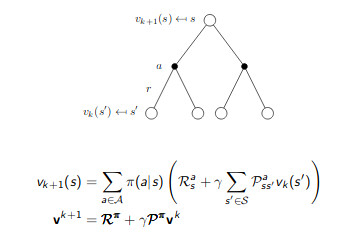
Lecture 3 - Dynamic Programming Dynamic Programming - Iterative Policy Evaluation, Policy Iteration, Value Iteration
Code: Dynamic Programming
-
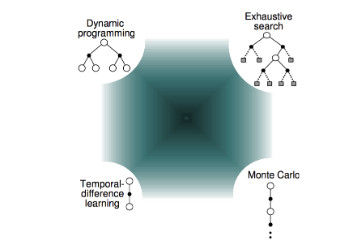
Lecture 4a - MC and TD Prediction Monte Carlo and Temporal Difference Prediction
Code: MC and TD Prediction
-
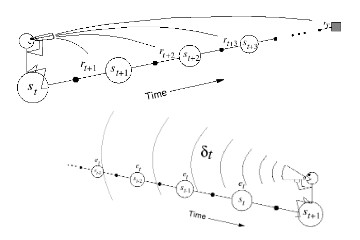
Lecture 4b - N-Step and TD(λ) Prediction Forward View TD(λ) and Backward View TD(λ) with Eligibility Traces
-

Lecture 5a - On-Policy Control On-Policy Control algorithms: MC Control, SARSA, N-Step SARSA, Forward View SARSA(λ), Backward View SARSA(λ) with Eligibility Traces
Code: On-Policy Control
-
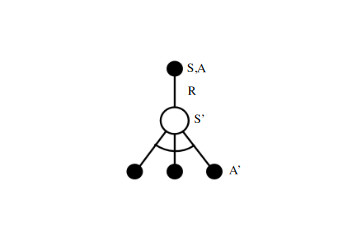
Lecture 5b - Off-Policy - Exp. Based Off-Policy Control algorithms (Expectation Based): Q-Learning, Expected SARSA, Tree Backup Algorithm
-
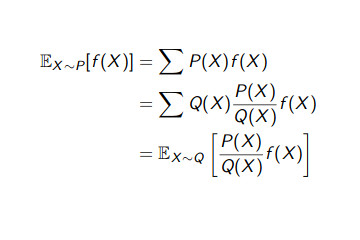
Lecture 5c - Off-Policy - Imp. Sampl. Off-Policy Control algorithms (Importance Sampling) - Imp.Sampl. SARSA, N-Step Imp.Sampl. SARSA, Off-Policy MC Control